<Java>13 Java 数据结构
本文最后更新于:2024年4月3日 下午
13 Java 数据结构
数据结构分为两种:线性结构、非线性结构
线性结构:
-
最常用的数据结构。数据元素间存在一对一线性关系。
-
线性结构有 2 种不同的存储结构:顺序储存结构,链式储存结构
顺序存储结构中元素存储在连续的内存空间中。
链式储存结构中元素储存在非连续的空间中,元素节点中存放数据元素及相邻元素的地址信息
-
常见的线性结构有:数组、队列、链表、栈等
非线性结构:
- 非线性结构包括:二维数组、多维数组、广义表、树结构、图结构
13.1 集合的框架体系
Java 提供了一系列集合容器,以方便程序员动态保存元素。并提供了一系列方便的操作对象的方法。
Java 集合主要分为两组:单列集合(Collection)、双列集合(Map)
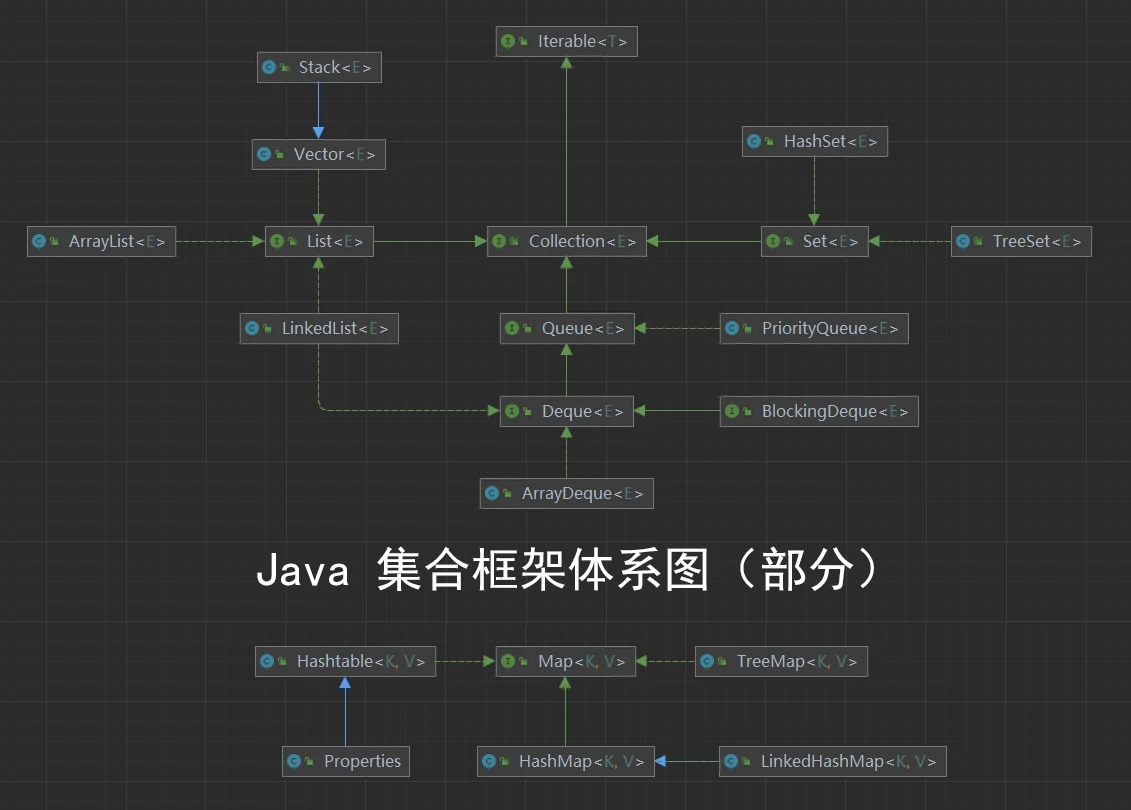
(集合体系图_13.1)
-
Collection 接口(单列集合):可以存放多个元素。每个元素可以是 Object
Collection 接口有两个重要子接口:List(有序集合)和 Set(无序集合)
-
Map 接口(双列集合):用于保存具有映射关系的数据:key - value(双列元素)
key 和 value 可以是任何类型的引用数据类型。其中 key 不能重复,value 可以重复
key 和 value 存在单一对应关系。通过特定的 key 一定能找到指定的 value
13.2 单列集合接口 Collection
public interface Collection<E> extends Lterable<E>Collection 实现子类可以存放多个元素。每个元素可以是 Object
有些 Collection 实现子类能存放重复的元素,有些不能
有些 Collection 实现子类是有序的(List) ,有些不是(Set)
Collection 接口没有直接的实现子类,都是通过其子接口实现的
常用方法:
-
add:添加单个元素ArrayList list = new ArrayList(); list.add("哈哈啊"); list.add(10); // 相当于List.add(new Integer(10)); list.add(true); // 同上 -
remove:删除单个元素list.remove(0) // 删除编号 0 的元素。上例中会删除 "哈哈啊" list.remove((Integer)10); // 删除上例的 10 要这样写 -
contains:检查元素是否存在 -
size:获取元素个数 -
isEmpty:判断是否为空 -
clear:清空 -
addAll:添加多个元素ArrayList list2 = new ArrayList(); list2.add(111); list2.add("idea"); list.addAll(list2); // 这里可以输入所有实现了 Collection 接口的集合 -
containsAll:检查多个元素是否存在list.contaionsAll(list2); // 同上,放一个实现了 Collection 接口的集合 -
removeAll:删除多个元素list.removeAll(list2); // 同上 -
Iterator iterator():返回指向集合开始位置的迭代器
13.2.1 迭代器 Iterator
Iterator 对象称为迭代器,主要用于遍历 Collection 集合中的元素。
Collection 继承的 Iterable 接口中,提供了
iterator()方法,会返回一个新的迭代器。Iterator 对象仅用于遍历集合,本身不存放元素
IDEA 中,迭代器 while 循环的模板快捷键:
itit
常用方法:
boolean hasNext():该方法判断是否有下一个元素。T next():该方法会将指针下移,然后返回下移后的位置上的元素
用迭代器遍历元素:
Collection<Object> c = new LinkedList<>();
Iterator<Object> iterator = c.iterator(); // [1]
while (iterator.hasNext()){ // [2]
Object obj = iterator.next(); // [3]
System.out.println(obj);
}-
获取迭代器
-
判断有无下一元素
-
将迭代器后移,并返回那个后移位置上的元素
while 循环结束后,指针指向最后元素的位置。再次
next()会报错。如果需要再使用,需要重置迭代器。iterator = list.iterator(); // 重置了迭代器
for each(增强 for 循环):
for each 的语法与 for 循环相似,但是可以遍历 Collection 和 数组 中的元素
IDEA 中,增强 for 循环的模板快捷键:
I
for (Object o : list){
...
}- for each 可在 Collection 集合中使用。
- for each 的底层在本质上也是
Iterator。可以理解为简化版本的迭代器遍历。
13.3 有序集合接口 List
public interface List<E> extends Collection<E>List 是 Collection 接口的子类接口
List 是有序(添加顺序和取出顺序一致)的,可重复的
List 中的每个元素都有其对应的顺序索引(从 0 开始编号)
常用方法:
-
add(int, obj):在 int 位置插入 obj 元素。返回 trueadd(obj):在末尾插入 obj。返回 truelist.add(111); list.add(0, 110); // 在第 1 个位置插入数字 110addElement(obj):在末尾插入 obj。无返回值。你说要这方法有啥用?名字还长一截 -
addAll(int, collection):在 int 位置插入 collection 中的所有元素 -
get(int):返回 int 位置的元素 -
indexOf(obj):返回 obj 首次出现时的位置 -
lastIndexOf(obj):返回 obj 最后一次出现时的位置 -
remove(int):移除 int 位置的元素,并返回那个被移除的元素 -
set(int, obj):设置 int 位置的元素为 obj。相当于替换。返回那个被替换元素的下标setElement(obj, int):设置 int 位置的元素为 obj。无返回值 -
subList(int1, int2):返回 [int1, int2) 范围的元素构成的子集合
13.3.1 可变数组 ArrayList
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.SerializableArrayList 是 List 的实现子类。其底层由数组来实现存储。
ArrayList 可以存放 null
#ArrayList 的源码:
-
ArrayList 中维护了一个 Object 类型的数组 elementData。该数组就是用来存放元素的数组
transient Object[] elementData; -
创建 ArrayList 对象时,如果使用无参构造器,则 elementData[] 初始容量为 0
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; public ArrayList() { this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; } -
如果使用指定大小构造器,则初始容量为指定大小。
private static final Object[] EMPTY_ELEMENTDATA = {}; public ArrayList(int initialCapacity) { if (initialCapacity > 0) { this.elementData = new Object[initialCapacity]; } else if (initialCapacity == 0) { /* 这个场合,与默认构造器的不同之处在于 扩容时,该 0 容量变为 1,而默认构造器会变为 10 */ this.elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException(...); } } -
扩容的场合:
如果是 无参构造器生成的初始 0 长度的 elementData,则将其容量置为 10。
否则容量扩容为 1.5 倍。
/* 扩容方法,传入的参数 minCapacity 是容器现有元素数量 + 1 的值 如果是无参构造器生成的默认数组,此时传入固定值 10 */ private void grow(int minCapacity) { int oldCapacity = elementData.length; /* 计算新的容量(旧容量的 1.5 倍) 此处 >> 为位运算符,等同于 newC = oldC + oldC / 2; */ int newCapacity = oldCapacity + (oldCapacity >> 1); /* 这里如果原容量是特殊值(1 或 0),容量会变为那个 minCapacity 的值 */ if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); }
13.3.2 可变数组 Vector
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.SerializableVector 是 List 的实现子类。其底层由数组来实现存储
Vector 与 ArrayList 基本等同。ArrayList 效率更高,Vector 线程安全。
在开发中,需要考虑线程安全时,建议使用 Vector ,而非 ArrayList。
#Vector 的源码:
-
底层维护了一个 Object 类型的数组 elementData。用以存放元素
protected Object[] elementData; -
使用无参构造器创建对象时,默认大小是 10
使用有参构造器的场合,默认是那个指定大小(initialCapaticy)
也能在构造器中指定那个扩容的增长速度(capacityIncrement)
public Vector() { this(10); } public Vector(int initialCapacity) { this(initialCapacity, 0); } public Vector(int initialCapacity, int capacityIncrement) { super(); if (initialCapacity < 0) throw new IllegalArgumentException(...); this.elementData = new Object[initialCapacity]; this.capacityIncrement = capacityIncrement; } -
扩容的场合,容量变成 2 倍
使用有参构造器改变了 capacityIncrement 的场合,增量是那个指定数值
private void grow(int minCapacity) { int oldCapacity = elementData.length; /* 计算新的容量(按照指定的增速扩容) 那个指定无效或未指定时,容量变为 2 倍 */ int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); }
13.3.3 链表 LinkedList
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable在 Java 中,LinkedList 是 List 的实现子类,底层以链表形式存储元素。
链表是一种非线性结构:其以节点方式存储,节点间在内存上的位置不连续。
链表是有序的列表。单向链表每个节点包含 data 域和 next 域。那些 next 域指向下一节点的位置。
双向链表在单向链表的基础上,每个节点加入 prev 区域以指示其前方节点。这样,就能实现双向查找。双向链表可以不依靠辅助节点而实现自我删除。
LinkedList 底层实现了 双向链表 和 双端队列 特点。在 Java 中,LinkedList 也实现了 Deque 接口。
LinkedList 可以添加 null,可添加重复元素。但没有实现同步,因此线程不安全。
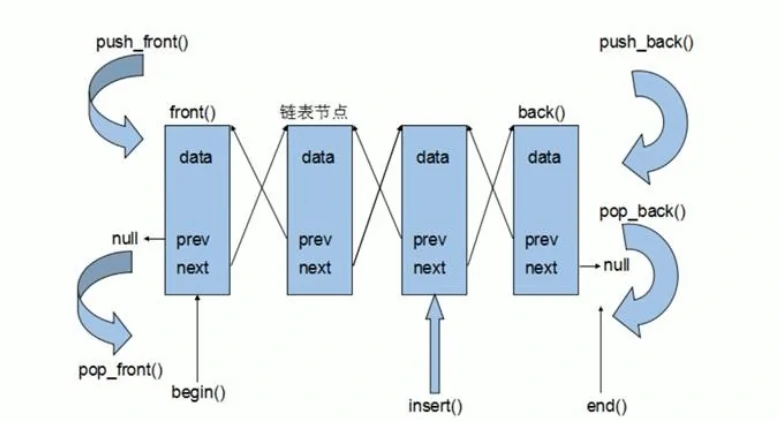
#常用方法:
-
void addLast(E e):尾插一个新的元素LinkedList 的 add 方法即调用该方法
-
void addFirst(E e):头插一个新的元素 -
E removeLast():移除并返回尾部元素。为空时报错E poll():移除并返回尾部元素。为空时返回 nullE removeFirst():移除并返回头部元素。为空时报错 -
E getLast():仅返回尾部元素。为空时报错E peek():返回尾部元素。为空时返回 nullE element():返回头部元素。为空时返回 nullE getFirst()
#LinkedList 的源码
-
LinkedList 只有默认构造器和一个拷贝构造器
public LinkedList() { } public LinkedList(Collection<? extends E> c) { this(); addAll(c); } -
LinkedList 底层维护了一个 双向链表
两个属性 first、last 分别指向 首节点 和 尾节点
每个节点(Node 对象),里面又维护了 prev、next、item 属性。
其中通过 prev 指向前一个节点,通过 next 指向后一个节点。最终实现双向链表。
transient Node<E> first; transient Node<E> last; private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } } -
LinkedList 不需要扩容。其增删元素时只要改变节点的指向即可。
也因此,其添加、删除元素效率比数组更高
#ArrayList 和 LinkedList 的比较:
| 底层结构 | 增删效率 | 改查效率 | |
|---|---|---|---|
| ArrayList | 可变数组 | 低(数组扩容) | 高 |
LinkedList |
双向链表 | 高(链表追加) | 低 |
应该根据实际情况来选择使用的集合:
-
如果改查操作多,选择 ArrayList。一般来说,在程序中,80% - 90% 都是查询。大部分情况下,选择 ArrayList。
-
如果增删操作多,选择 LinkedList
13.3.4 稀疏数组
二维数组的很多值是默认值 0,因此记录了很多没有意义的数据。因此,可以使用稀疏数组。
稀疏数组的处理方法:
- 记录数组共有几行几列,有多少个不同的值
- 把具有不同值的元素的行列及值记录在一个小规模数组中,从而缩小程序规模
二维数组转换为稀疏数组:
下面用 ArrayList 模拟一个稀疏数组。
二维数组:
int[][] map = {{0, 2, 0, 0, 0, 0 ,0 , 0},
{0, 0, 3, 0, 0, 0, 0, -1},
{15, 0, 0, 0, 0, 4, 0, 0},
{0, 2, 0, 0, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0, 0, 0},
{0, 0, 0, 0, 0, 0, 0, 1},
{0, 0, 0, 0, 0, 0, 0, 0}};遍历原始的二维数组,得到有效数据的个数 sum,并将二维数组的有效数据存入稀疏数组
List<int[]> sparseArray = new ArrayList();
sparseArray.add(new int[]{map.length, map[0].length, 0}); //
for (int y = 0; y < map.length; y++) {
for (int x = 0; x < map[0].length; x++) {
if (map[y][x] != 0) {
sparseArray.add(new int[]{y, x, map[y][x]});
sparseArray.get(0)[2]++;
}
}
}稀疏数组转化为二维数组:
读取稀疏数组的每一行,按照其第一行数据,创建原始的二维数组。
读取后几行数据,将值赋给二维数组
13.3.5 栈 Stack
public class Stack<E> extends Vector<E>Stack 是 Vector 的子类。以数组模拟了栈的数据结构。
栈是一个先入后出的有序列表。其元素之插入删除只能在该线性表的同一端进行。
其允许增删的一端称为栈顶,另一端即为栈底。
最先放入的元素位于栈底,最后放入的元素位于栈顶。
放入元素称为入栈(push),取出元素称为出栈(pop)
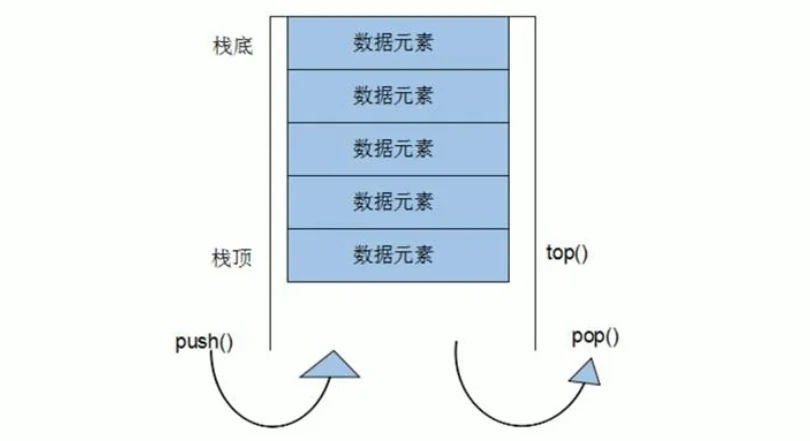
栈的应用场景:
- 子程序的调用
- 处理递归调用
- 表达式的转换与求值
- 二叉树的遍历
- 图形的深度优先搜索法
#常用方法:
-
E push(E item):将元素 item 压入栈。返回值是 item 自己 -
E pop():让栈顶元素出栈 -
E peek():仅获取栈顶元素 -
int search(Object o):查找该元素最后出现的位置。栈底为 1,栈顶为 size(),不存在返回 -1
#13.3.5.1 栈模拟计算器
使用栈结构完成对计算器的实现
要进行计算,需要获得表达式。
表达式分为三种:
-
中缀表达式:
中缀表达式即生活中常见的运算表达式。比如:(3 + 4) * 5 - 6
中缀表达式是人最熟悉的。但是对于计算机来说却不好操作。因此,计算时常将其转化为其他表达式进行操作。
-
前缀表达式:
前缀表达式(波兰表达式)是一种没有括号的表达式。其将运算符写在前面,操作数写在后面
(3 + 4) * 5 - 6 的前缀表达式为: + 3 * 4 - 5 6
(1 + 2) * (3 + 4) 的前缀表达式为:* + 1 2 + 3 4
前缀表达式的计算机求值:
- 从右向左扫描表达式
- 将数字压入堆栈
- 遇到运算符的场合,对数字栈顶元素与次顶元素进行计算,并把那个结果入栈
- 重复该操作,最终数字栈的唯一剩余数字即为运算结果
-
后缀表达式:
后缀表达式(逆波兰表达式)与前缀表达式相似。但其运算符位于操作数之后
(3 + 4) * 5 - 6 的后缀表达式为: 3 4 + 5 * 6 -
(1 + 2) * (3 + 4) 的后缀表达式为:1 2 + 3 4 + *
后缀表达式的计算机求值:
- 从左向右扫描表达式
- 将数字压入堆栈
- 遇到运算符的场合,对数字栈顶元素与次顶元素进行计算,并把那个结果入栈
- 重复该操作,最终数字栈的唯一剩余数字即为运算结果
对于人类来说,中缀表达式最为熟悉。但对于计算机来说,前缀、后缀表达式更容易识别。
我们可以将中缀表达式转化为后缀表达式,再进行运算。
中缀表达式转换为后缀表达式:
-
初始化两个栈:运算符栈 operator_stack、表达式栈 formula_stack
-
从左到右扫描中缀表达式
-
遇到操作数时,将其压入表达式栈 formula_stack
-
遇到运算符时,比较其与 operator_stack 栈顶运算符的优先级。
- operator_stack 为空,或栈顶为
(的场合,让运算符入栈 - 优先级高于栈顶运算符的场合,让其入栈
- 优先级低于或等于栈顶运算符的场合,将那个堆顶运算符弹出并压入 formula_stack。之后,重复该步骤。
- operator_stack 为空,或栈顶为
-
遇到括号时:
- 遇到
(时,压入 operator_stack - 遇到
)时,直到遇到(前,依次弹出 operator_stack 堆顶的运算符,并压入 formula_stack。之后将这一对括号丢弃。
- 遇到
-
到达表达式最右边时,依次弹出 operator_stack 堆顶的运算符,压入 formula_stack。
-
此时,formula_stack 即为后缀表达式。
使用 Java 的 toArray 方法将其转为数组。或将其依次弹出,并逆序输出。
计算器的实现:
class Calculator {
private static final Map<Character, Integer> priority = new HashMap<>();
static {
priority.put('+', 1);
priority.put('-', 1);
priority.put('*', 2);
priority.put('/', 2);
priority.put('×', 2);
priority.put('÷', 2);
priority.put('(', -100);
priority.put(')', -10);
}
public static double calculate(String formula) {
String[] ss = formula.split(" ");
Stack<String> operator_stack = new Stack<>();
Stack<String> formula_stack = new Stack<>();
for (String s : ss) {
if (s.matches("\\d+([.]\\d+)?")) {
formula_stack.push(s);
continue;
} else if (operator_stack.empty() || s.equals("(")) {
operator_stack.push(s);
continue;
}
String temp = operator_stack.peek();
while (priority.get(s.charAt(0)) <= priority.get(temp.charAt(0))) {
formula_stack.push(operator_stack.pop());
if (operator_stack.empty()) break;
temp = operator_stack.peek();
}
if (s.equals(")")) {
operator_stack.pop();
} else operator_stack.push(s);
}
while (!operator_stack.empty()) {
formula_stack.push(operator_stack.pop());
}
return anti_Poland(String.join(" ", formula_stack.toArray(new String[]{})));
}
private static double anti_Poland(String formula) {
String[] ss = formula.split(" ");
Stack<Double> ns = new Stack<>();
for (String s : ss) {
try {
double num = Double.parseDouble(s);
ns.push(num);
} catch (Exception e) {
switch (s) {
case "+":
ns.push(ns.pop() + ns.pop());
break;
case "*":
case "×":
ns.push(ns.pop() * ns.pop());
break;
case "/":
case "÷":
ns.push(1 / ns.pop() * ns.pop());
break;
case "-":
ns.push(-ns.pop() + ns.pop());
break;
default:
throw new RuntimeException("Illegal operator");
}
}
}
return ns.pop();
}
}13.3.6 跳表 SkipList
跳表是一种特殊的链表。普通的链表虽然添加、删除节点的速度很快(O(1)),但是要查找节点却很慢(O(n))。跳表是一个多层次的链表,其在链表的基础上增加了多级索引,实现了 O(㏒n) 的查找速度。
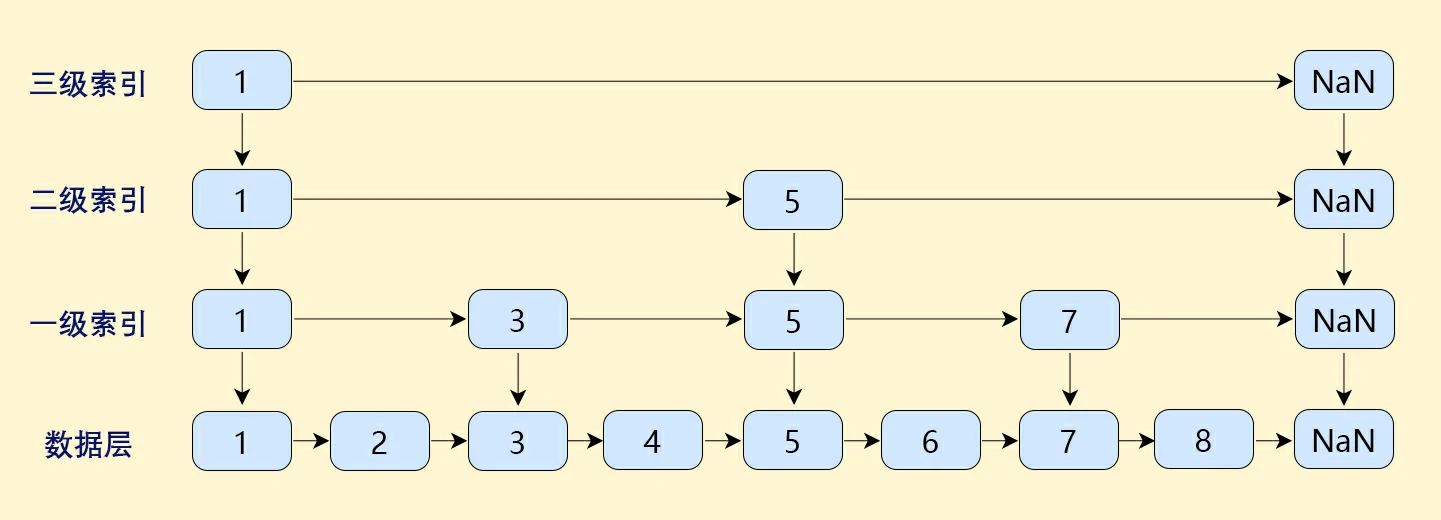
(13_3_6 跳表图)
跳表将原本数据层的数据按照一定间隔抽取节点形成索引层,之后再从索引层抽取节点形成第二级索引,以此类推形成多层索引。
跳表的查询速度得到了优化,但占用空间更大。本质上是一种空间换时间的做法。
查询
从最稀疏的索引层(最上层)开始,确定那个待查找数据所在的范围,逐层向下并确定范围,直至数据层。
增删
删除元素时,如果那个元素是索引元素,那些索引也会被删除。同时,如果只向数据层中增加元素,可能使索引间隔过大,从而降低查找效率。如果在增加元素时还能保持索引数量的动态平衡,就能防止跳表退化,保持跳表效率。
跳表给出的解决方案是:在增加元素时产生一个随机值,让这个随机值决定该新节点是否成为索引节点,以及成为几级索引节点。
实现跳表
class Skiplist {
private final int level; // 该跳表的合计层数,包括数据层和索引层
private final Random seed; // 随机数种子
private final Node root; // 链表开头
private final Node end; // 链表结尾
private static class Node { // 链表节点类
int val; // 值
int count; // 储存的值的数量
Node[] next; // 指向的下一节点
Node[] prev; // 指向的上一节点
// 需要指出的是:next 和 prev 的长度指示了节点所在的最高层级
// 长度为 1 时仅处在数据层,2 时也位于一级索引,以此类推
// 也就是说,next 和 prev 里,下标 0 的位置位于数据层,1 位于一级索引层
/* 三个参数是:值 val,节点的层级 rand,节点储存值的数量 count */
Node(int val, int rand, int count) {
this.val = val;
this.count = count;
next = new Node[rand];
prev = new Node[rand];
}
}
/* 构造器 */
public Skiplist() {
this(4);
}
/* 有参构造器。输入的值是索引层数量。该值至少应为 1 */
public Skiplist(int level) {
if (level < 1 || level > 30)
throw new RuntimeException(level == 0 ?
"Why not choose a LinkedList?" :
"SkipList level out of range: given " + level + " out of range [1, 30]");
this.level = level + 1;
this.seed = new Random(System.currentTimeMillis());
root = new Node(Integer.MIN_VALUE, this.level, 0);
end = new Node(Integer.MAX_VALUE, this.level, 0);
for (int n = 0; n < this.level; n++) {
root.next[n] = end;
end.prev[n] = root;
}
}
/* 查询一个值是否存在 */
public boolean search(int target) {
Node find = position(target);
return find.val == target && find.count > 0;
}
/* 搜索一个值的位置。不存在时会返回数据层中前一个节点的位置 */
private Node position(int target) {
Node see = root;
while (true) {
if (see.val == target) return see;
for (int n = see.next.length - 1; ; n--) {
if (n < 0) return see;
else if (see.next[n].val <= target) {
see = see.next[n];
break;
}
}
}
}
/* 添加一个值 */
public void add(int num) {
Node pos = position(num);
if (pos.val == num) { // 如果这个节点已经建立,就仅使该节点计数增加
pos.count++;
return;
}
int rand = 1 + level - Integer.toBinaryString(seed.nextInt(1 << level)).length();
// level 的值等于总层数。seed 是一个随机数种子,nextInt(int n) 方法返回 [0, n) 的数值
// Integer.toBinaryString(int n) 方法是将一个数字转化成二进制表示的字符串
// seed.nextInt(1 << level) 保证了返回值的二进制长度在 [1, level] 之间,并且概率合意
Node add = new Node(num, rand, 1);
for (int t = 0; t < rand; ) { // 将新节点添加到链表中。
for (; t < pos.next.length && t < rand; t++) {
Node next = pos.next[t];
add.next[t] = next;
next.prev[t] = add;
pos.next[t] = add;
add.prev[t] = pos;
}
pos = pos.prev[pos.prev.length - 1];
}
}
/* 删除节点(的值) */
public boolean erase(int num) {
Node pos = position(num);
if (pos.val == num && pos.count > 0) {
pos.count--;
return true;
} else return false;
}
}13.4 队列接口 Queue
public interface Queue<E> extends Collection<E>Queue 是 Collection 的子接口
Queue 的实现子类都是队列式集合。队列是一个有序列表,可以用数组或链表来实现
队列遵循先入先出的原则。队列中元素是以添加顺序取出的。
向队列中增加元素称为入列(push),取出元素称为出列(pop)
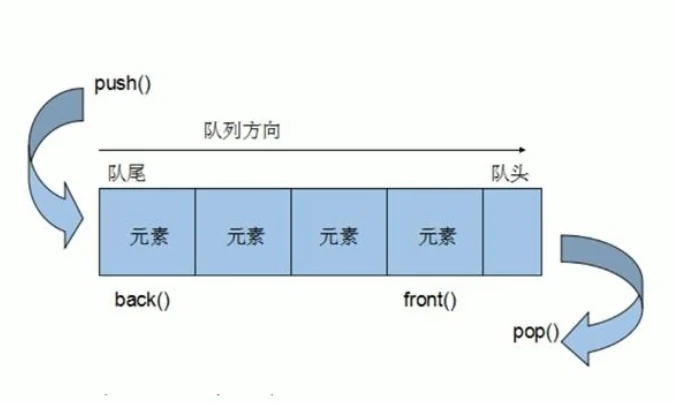
常用方法:
-
add(E e):添加元素。队列满的场合抛出异常put(E e):添加元素。队列满的场合可能阻塞boolean offer(E e):添加元素。队列满的场合返回 false -
E remove():移除并返回队列头部元素。队列空的场合抛出异常E poll():移除并返回队列头部元素E take():移除并返回队列头部元素。队列空的场合可能阻塞 -
E peek():仅返回队列头部元素。为空时返回 nullE element():仅返回队列头部元素。为空时抛出异常
13.4.1 优先级队列 PriorityQueue
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.SerializablePriorityQueue 是一个无界优先级队列。底层以数组储存元素。
无界队列:即没有范围限制的队列。
PriorityQueue 不允许 null 元素,也不允许不可比较的元素。
PriorityQueue 中的元素以自然顺序,或传入的比较器决定的顺序排序。其中的最小元素位于队头,最大元素位于队尾。
以迭代器遍历时,会按照原本的放入顺序获取元素。PriorityQueue 的源码:
-
底层维护了一个 Object 类型的数组 queue。用以存放元素
另维护了一个比较器 comparator,用以比较元素
transient Object[] queue; private final Comparator<? super E> comparator; -
默认构造器初始容量为 11,比较器为 null
也能指定初始容量,或传入比较器
public PriorityQueue() { this(DEFAULT_INITIAL_CAPACITY, null); } public PriorityQueue(int initialCapacity) { this(initialCapacity, null); } public PriorityQueue(Comparator<? super E> comparator) { this(DEFAULT_INITIAL_CAPACITY, comparator); } public PriorityQueue(int initialCapacity, Comparator<? super E> comparator) { if (initialCapacity < 1) throw new IllegalArgumentException(); this.queue = new Object[initialCapacity]; this.comparator = comparator; } -
放入时依靠比较器 comparator 进行排序。
那个比较器为 null 的场合,每次放入元素会按元素自身的自然顺序进行排序。
不能排序的场合会抛出异常。
-
扩容时,容量小于 64 的场合容量变为 2 倍 + 2。否则那个容量变为 1.5 倍
private void grow(int minCapacity) { int oldCapacity = queue.length; int newCapacity = oldCapacity + ((oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1)); if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); queue = Arrays.copyOf(queue, newCapacity); }
13.4.2 阻塞队列接口 BlockingQueue
public interface BlockingQueue<E> extends Queue<E>BlockingQueue 是一个接口,其实现子类都是阻塞队列。
阻塞队列:
- 元素入列时,那个队列已满的场合,会进行等待。直到有元素出列后,元素数量未超过队列总数时,解除阻塞状态,进而继续入列。
- 元素出列时,如果队列为空,则会进行等待。直到有元素入列时,解除阻塞状态,进而继续出列。
- 阻塞队列能防止容器溢出。只要是阻塞队列,就是线程安全的队列。
- 阻塞队列不接受 null 元素
常用方法
实际上,其常用方法能分为几类
| 队列为空/满时… | 抛出异常 | 特殊值 | 阻塞 | 等待 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 删除 | remove() | poll() | take() | take(time, unit) |
| 查找 | element() | peek() | - | - |
BlockingQueue 的常用实现子类
- ArrayBlockingQueue:底层以数组存放元素的有界阻塞队列
- LinkedBlockingQueue:底层以链表存放元素的可选边界的阻塞队列
- PriorityBlockingQueue:优先级阻塞队列,与 PriorityQueue 排序方式相同
13.4.3 双端队列接口 Deque
public interface Deque<E> extends Queue<E>Deque 是 Queue 的子接口。
Deque 的实现子类都是双端队列。双端队列的两端都可以添加、删除。可见,Deque 双端队列既有队列的特性,又有栈的特性。
常用方法
Deque 接口同样提供了一系列方法
| 操作的是… | 头元素 | 尾元素 | ||
|---|---|---|---|---|
| 队列为空/满时… | 抛出异常 | 特殊值 | 抛出异常 | 特殊值 |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | odderLast(e) |
| 删除 | removeFirst(e) | pollFirst(e) | removeLast(e) | pollLast(e) |
| 查找 | getFirst(e) | peekFirst(e) | getLast(e) | peekLast(e) |
Deque 的常用实现子类
- LinkedList:双向链表。在 Java 中,LinkedList 也实现了 Deque 接口。
- ArrayDeque:基于数组实现的双端队列。
- LinkedBlockingDeque:以双向链表实现的,双端阻塞队列。该类事实上也继承了 BlockingQueue 接口。
13.5 双列集合接口 Map
public interface Map<K,V>以下关于 Map 接口的描述,适用于 JDK 8 的环境
Map 与 Collection 并列存在,用于保存具有映射关系的数据:key - value(双列元素)
Map 的 key 和 value 可以是任何类型的引用数据类型,也能存入 null。
Map 的 key 不允许重复,value 可以重复。key 和 value 存在单一对应关系。通过特定的 key 一定能找到指定的 value。
一组 k - v 会被封装到一个 Entry 对象中。Entry 是一个内部接口。Map 的实现子类中都包含一个实现这个接口的内部类。
interface Entry<K,V> { K getKey(); V getValue(); ... }如果添加相同的 key,会覆盖原先的 key -value。等同于修改(key 不会替换,value 会被替换)
#常用方法:
-
put():添加。已存在的场合,实行替换。(key 不替换,value 替换) -
remove():根据键删除映射关系 -
get():根据键获取值 -
size():元素个数 -
isEmpty():判断个数是否为 0 -
clear():清空 -
containsKey():查找键是否存在 -
Set<K> keySet():获取所有 键 构成的集合Set<Map.Entry<K,V>> entrySet():获取所有 Entry 构成的集合Collection<V> values():获取所有 值 构成的集合
#Map 接口遍历元素:
-
方法一:利用
Set<K> keySet()方法先得到所有 keys,再遍历 keys,根据每个 key 获得 value:
Set keyset = map.keySet(); for (Object o : keyset) { System.out.println(o + " = " + map.get(o)); } -
方法二:利用
Set<V> values()方法直接把所有 values 取出,之后遍历 values
Collection values = map.values(); for (Object value : values) { System.out.println(value); } -
方法三:利用
Set<Map.Entry<K,V>> entrySet()方法通过获取 entrySet 来获取 k - v
Set<Map.Entry> entrySet = map.entrySet(); for (Map.Entry e : entrySet) { System.out.println(e.getKey() + " - " + e.getValue()); }
13.5.1 散列表 HashMap
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, SerializableHashMap 是 Map 接口使用频率最高的实现类。是根据关键码值(key value)而进行直接访问的数据结构。通过将关键码值映射到表中一个位置来访问记录,以加快查找速度。
那个映射函数叫做散列函数,存放记录的数组叫做散列表(哈希表)
HashMap 是以 k - v 对得到方式来存储数据。一组数据会被封装到一个 Node 对象中。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; ... }JDK 7 前,HashMap 底层是 数组 + 链表。JDK 8 后,底层是 数组 + 链表 + 红黑树。HashMap 不保证映射的顺序。
HashMap 没有实现同步(没有 synchronized),是线程不安全的
#HashMap 的源码:
-
HashMap 底层维护了 Node 类型的数组 table。默认为 null
transient Node<K,V>[] table;另外,还有集合 values、keySet、enrtySet。这些集合能帮助程序员进行遍历
transient Set<K> keySet; transient Collection<V> values; transient Set<Map.Entry<K,V>> entrySet; -
创建对象时,默认构造器将加载因子(loadfactor)初始化为 0.75。
也能指定那些初始容量和加载因子。
默认构造器第一次添加元素的场合,table 扩容为 16,临界值为 16 * 0.75 = 12。
static final float DEFAULT_LOAD_FACTOR = 0.75f; static final int MAXIMUM_CAPACITY = 1 << 30; public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // 这个默认构造的场合,其他参数都是默认值 } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException(...); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException(...); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); } -
添加时容量不够的场合,需要扩容。
默认构造器第一次添加元素的场合,table 扩容为 16,临界值为 16 * 0.75 = 12。
扩容的场合,容量变为 2 倍。临界值相应变化。
临界值不会超过那个指定的 MAXIMUM_CAPACITY(1 << 30),否则变成 Integer.MAX_VALUE。
JDK 8 中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是 8),并且
table的大小 >= MIN_TREEIFY_CAPACITY(默认 64),会进行树化。剪枝:红黑树的元素减少到一定程度,会被重新转化为 链表
static final int MAXIMUM_CAPACITY = 1 << 30; static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; // <- 旧的数据数组 table int oldCap = (oldTab == null) ? 0 : oldTab.length; // <- 旧的 table 的容量 int oldThr = threshold; // <- 旧的临界值 int newCap, newThr = 0; // <- 新的容量、临界值 /* 旧的数组不为空时, 如果容量已达指定的 MAXIMUM_CAPACITY,则不扩容 否则扩容为 2 倍容量,临界值也变为 2 倍 */ if (oldCap > 0) { newCap = oldCap << 1; if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if (newCap < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; } /* 旧的数组为空,但临界值已被指定(原因是:指定构造器传入初始容量为 0) */ else if (oldThr > 0) newCap = oldThr; /* 旧的数组为空,临界值为 0(原因是:使用默认构造器) 默认构造器初始化容量为 16,默认临界因子为 0.75f */ else { newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } /* 到这里,newThr(新临界值)为 0 的原因可能是: 1. 旧容量小于那个最小容量(16) 2. 扩容后容量大于那个最大容量 3. 旧的临界值为 0 或 Integer.MIN_VALUE 4. 构造器传入初始容量为 0 */ if (newThr == 0) { /* 按照 新容量 * 临界因子 的方法计算临界值。临界值不会超过一个指定的最大值 */ float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; /* 确定了容量和临界值,下面把旧数组元素移至新数组。 那个移动的场合,会以新容量重新计算所有元素的下标位置 */ Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; } -
添加 k - v 时,通过 key 的哈希值得到其在 table 的索引,判断索引位置是否被占用。
未占用的场合,直接添加。
占用的场合,判断其 key 是否相等。相等的场合,替换 value。否则,按照 树 或 链表 的方式处理。
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } /* 会先对放入元素的哈希值进行一次计算,得到一个数字:hash */ static final int hash(Object key) { int h = key.hashCode(); return (key == null) ? 0 : (h ^ (h >>> 16)); // 位运算符:>>> 无符号右移 } /* put 方法会调用该 putVal 方法。 那些传入值是: hash、 key、 value、 false、 true */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab = table; // <- 是那个存放数据的 table 数组 int n; // <- 是 table.length /* 如果原先的 table 为空,则对其重新分配空间 */ if (tab == null || (n = tab.length) == 0) { tab = resize(); n = tab.length; } /* 用方才计算的 hash 数,得到要放入元素的下标值 i n - 1 是数据数组的最大下标,(n - 1) & hash 必定不大于 n - 1 */ int i = (n - 1) & hash; // 位运算符:& 按位与 Node<K,V> p = tab[i]; // 得到 table 中,位于那个插入位置的元素 /* 倘若该位置为空,则直接放入 */ if (p == null) { tab[i] = newNode(hash, key, value, null); } /* 该位置不为空,意味着可能添加了重复元素 */ else { Node<K,V> e; // <- 被发现重复的那个 Node。无重复时结果为 null。这个 Node 的 value 会被替换。 K k = p.key; // <- 当前取出进行比较的 key 值 /* 为了验证其是否重复,这里要进行如下比较: 1. 比较两者的 hash 数。不同的场合是不同元素 2. 使用 == 和 equals 两种方法比较 key。不同的场合是不同元素 如果是相同元素,则该节点的值会被替换 */ if (p.hash == hash && (k == key || (key != null && key.equals(k)))) { e = p; } /* 此处节点结构是 树 的场合,还需遍历比较树的每个节点 */ else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); /* 此处节点结构是 链表 的场合,还需遍历比较每个链表节点 */ else { for (int binCount = 0; ; ++binCount) { e = p.next; /* e == null 意味着遍历结束,全部不同。这样,在此处添加那个新的 Node */ if (e == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } /* 故技重施,如果发现相同,则替换那个新元素 */ if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { break; } p = e; } } /* 经历上述比较后,e != null 意味着有元素要被替换了 */ if (e != null) { V oldValue = e.value; /* 传入的参数 onluIfAbsent == false,所以此处一定是 true */ if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); // <- HashMap 中,该方法为空实现。 return oldValue; } } ++modCount; /* 如果到达这里,说明添加了元素(而非替换),要查看大小是否超过临界值 */ if (++size > threshold) resize(); afterNodeInsertion(evict); // <- HashMap 中,该方法为空实现。 return null; } /* 上面提到的一些空实现的方法 */ void afterNodeAccess(Node<K,V> p) { } void afterNodeInsertion(boolean evict) { } void afterNodeRemoval(Node<K,V> p) { }
13.5.2 散列表 Hashtable
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.SerializableHashtable 和 HashMap 基本一致,但Hashtable 是线程安全的 。但也因为如此,Hashtable 的效率低下。
#Hashtable 与 HashMap 的比较:
| 版本 | 线程安全(同步) | 效率 | 是否允许 null值 | |
|---|---|---|---|---|
| Hashtable | 1.0 | 安全 | 较低 | 不允许 |
| HashMap | 1.2 | 不安全 | 高 | 允许 |
-
Hashtable 底层也是有数组,默认构造器的初始容量为 11。临界值是 11 * 0.75 = 8。
-
扩容大致如下:
int newCapacity = (oldCapacity << 1) + 1; //即,原容量 * 2 + 1 -
Hashtable 不会树化
13.5.3 红黑树 TreeMap
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.SerializableTreeMap 实现了 Map 接口。底层使用 红黑树 存储数据。
相较数组(访问快,检索、插入慢)和链表(插入快,检索、访问慢),树形数据结构(如二叉排序树)在保证数据检索速度的同时,也能保证数据插入、删除、修改的速度
——见 [14.1.4.1 平衡二叉树]
#TreeMap 的源码:
-
TreeMap 底层维护了一个二叉树,以及一个比较器
private final Comparator<? super K> comparator; private transient Entry<K,V> root; -
创建对象时,能采用无参构造,也能指定比较器完成构造
那个无参构造的场合,比较器为空。
public TreeMap() { comparator = null; } public TreeMap(Comparator<? super K> comparator) { this.comparator = comparator; }比较器如果为空,则要求传入的 key 必须是 Comparable 接口的实现子类,否则无法进行比较。
final int compare(Object k1, Object k2) { return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2) : comparator.compare((K)k1, (K)k2); } -
添加时,通过比较器确定那个添加位置。
public V put(K key, V value) { Entry<K,V> t = root; // <- 树的根节点 /* 二叉树为空的场合,创建根节点,将数据放入 */ if (t == null) { compare(key, key); root = new Entry<>(key, value, null); size = 1; modCount++; return null; } int cmp; // <- 临时值,存放比较结果 Entry<K,V> parent; // <- 临时值,存放父节点 Comparator<? super K> cpr = comparator; // <- 比较器 /* 有比较器的场合,按照这个方法进行比较 */ if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } /* 比较器为空的场合,按照这个方法进行比较 */ else { if (key == null) { throw new NullPointerException(); } Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } /* 将数据节点放到正确的路径下 */ Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; /* 此处会试着将该树转换成完全二叉树 */ fixAfterInsertion(e); size++; modCount++; return null; } -
添加的最后,会试着将该树转换成完全二叉树
private void fixAfterInsertion(Entry<K,V> x) { x.color = RED; while (x != null && x != root && x.parent.color == RED) { if (parentOf(x) == leftOf(parentOf(parentOf(x)))) { Entry<K,V> y = rightOf(parentOf(parentOf(x))); if (colorOf(y) == RED) { setColor(parentOf(x), BLACK); setColor(y, BLACK); setColor(parentOf(parentOf(x)), RED); x = parentOf(parentOf(x)); } else { if (x == rightOf(parentOf(x))) { x = parentOf(x); rotateLeft(x); } setColor(parentOf(x), BLACK); setColor(parentOf(parentOf(x)), RED); rotateRight(parentOf(parentOf(x))); } } else { Entry<K,V> y = leftOf(parentOf(parentOf(x))); if (colorOf(y) == RED) { setColor(parentOf(x), BLACK); setColor(y, BLACK); setColor(parentOf(parentOf(x)), RED); x = parentOf(parentOf(x)); } else { if (x == leftOf(parentOf(x))) { x = parentOf(x); rotateRight(x); } setColor(parentOf(x), BLACK); setColor(parentOf(parentOf(x)), RED); rotateLeft(parentOf(parentOf(x))); } } } root.color = BLACK; }
13.5.4 Properties
Properties 继承自 Hashtable 并实现了 Map 接口。也使用键值对的方式保存数据
Properties 使用特点与 Hashtable 相似
Properties 还可以用于 xxx.properties 文件中,加载数据到 Properties 对象,进行读取和修改
xxx.properties 文件常作为配置文件
public class Properties extends Hashtable<Object,Object>——关于这些,详见 [17 IO流 ]
-
String getProperty(String key):输入一个 String 类型的 key,返回一个 String 的 valuepublic String getProperty(String key) { Object oval = super.get(key); String sval = (oval instanceof String) ? (String)oval : null; return ((sval == null) && (defaults != null)) ? defaults.getProperty(key) : sval; }
13.6 无序集合接口 Set
Set 是 Collection 接口的子类接口。
Set 接口的特点是无序(添加和取出顺序不一致,其取出顺序由某个算法决定),没有索引
不允许重复元素。故而,最多包含一个 null
public interface Set<E> extends Collection<E>13.6.1 HashSet
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.SerializableHashSet 实现了 Set 接口。底层实际上使用 HashMap 来存储数据。
身在 Collection 心在 MapHashSet 是无序的。其实际顺序取决于计算得到的 hash 值
#HashSet 的源码
-
HashSet 底层是 HashMap。
private transient HashMap<E,Object> map; -
实例化也和 HashMap 相同
public HashSet() { map = new HashMap<>(); } public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); } public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } -
添加一个元素时调用 HashMap 的方法
public boolean add(E e) { return map.put(e, PRESENT)==null; }
13.6.2 LinkedHashSet
LinkedHashSet 是 HashSet 的子类
LinkedHashSet 底层是一个 LinkedHashMap,维护了一个数组 + 双向链表。
有其父必有其子LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置。同时,使用链表维护元素的次序。这使得元素看起来是以插入顺序保存的,并得以按照放入顺序取出
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable#LinkedHashSet 的源码:
-
在类 HashSet 中,存在一个默认访问范围的构造器。该构造器不同于其他构造器,会让实例维护一个 LinkedHashMap
HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }LinkedHashSet 的构造器即调用了该父类构造器
public LinkedHashSet(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor, true); } public LinkedHashSet(int initialCapacity) { super(initialCapacity, .75f, true); } public LinkedHashSet() { super(16, .75f, true); }
13.6.3 TreeSet
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.SerializableTreeSet 实现了 Set 接口,其底层是一个 TreeMap。
好家伙,原来 Set 全家都是卧底调用无参构造器创建 TreeSet 时,默认是无序排列。也能在构造时传入一个比较器。有比较器的场合,比较器返回 0 时,不发生替换
不传入比较器的场合,使用的是传入对象自带的比较器。所以,这个场合,传入的 key 对象必须是 Comparable 接口的实现子类
13.7 集合的选择
在开发中,选择什么集合实现类,主要取决于业务操作特点,然后根据集合实现类特性进行分析选择。
判断存储的类型(一组对象 [单列],或一组键值对 [双列])
- 一组对象:Collection 接口
- 允许重复:List
- 增删多:
LinkedList(双向链表) - 改查多:ArrayList (
Object[]数组)
- 增删多:
- 不允许重复:Set
- 无序:HashSet (数组 + 链表 + 红黑树,底层是 HashMap)
- 排序:
TreeSet - 顺序一致:LinkedHashSet (数组 + 双向链表,底层是
LinkedHashMap)
- 允许重复:List
- 一组键值对:Map
- 键无序:HashMap (数组 + 链表 + 红黑树 [ JDK 8 以后 ] )
- 键排序:
TreeMap - 键顺序一致:
LinkedHashMap(底层是 HashMap) - 读取文件:Properties
13.8 工具类 Collections
Collections 工具类是一个操作 Set、List、Map 等集合的工具类
其中提供了一系列静态方法,对集合元素进行 排序、查询和修改等操作
#常用方法:
排序:
reverse(List):反转 List 中元素的排序shuffle(List):对List中元素进行随机排序sort(List):根据元素的自然顺序对指定 List 集合元素升序排列reverse(List, Comparator):根据指定 Comparator 对 List 排序swap(List, int, int):将两处元素位置互换
查找、替换:
-
Object max(Collection):根据元素的自然排序,返回集合中最大的元素 -
Object max(Collection, Comparator):根据比较器,返回最大元素 -
Object min(Collection):根据元素的自然排序,返回最小元素 -
Object min(Collection, Comparator):根据比较器,返回最小元素 -
int frequency(Collection, Object):返回集合中指定元素的出现次数 -
void copy(List dest, List src):将 src 的内容复制到 dest 中这个场合,要保证 dest 的大小不小于 src。所以,可能需要先给 dest 赋值
-
boolean replaceAll(List list, Object oldVal, Object newVal):用 newVal 替换所有 oldVal 值
13.9 JUnit
一个类有多个功能代码需要测试,为了测试,就要写入
main方法中如果有多个功能代码测试,需要反复撤销,过程繁琐
JUnit 是一个 Java 语言单元测试框架
多数 Java 开发环境都已集成了 JUnit 作为单元测试工具
……总的来讲,方法就是加入
@Test,然后alt + enter引入 JUnit 5,最后运行