<计算机系统结构>CA6 标量处理机、向量处理机
本文最后更新于:2024年3月23日 晚上
CA6 标量处理机、向量处理机
CA6.1 重叠方式
一条指令的执行分为三个阶段:取出指令、分析指令、执行指令
执行时有三种执行方式:
-
顺序执行方式:完全顺序地执行所有指令
gantt dateFormat x axisFormat %Q section 取指令 指令 A: 0, 1 指令 B: 3, 4 指令 c: 6, 7 section 分析指令 指令 A: 1, 2 指令 B: 4, 5 指令 c: 7, 8 section 执行指令 指令 A: 2, 3 指令 B: 5, 6 指令 c: 8, 9其花费时间(假设取指令、分析、执行指令时间相等)有:
虽然控制简单,但处理机执行指令速度慢,功能部件利用率低
-
一次重叠执行方式:执行指令时,即取出下一指令
gantt dateFormat x axisFormat %Q section 取指令 指令 A: 0, 1 指令 B: 2, 3 指令 C: 4, 5 section 分析指令 指令 A: 1, 2 指令 B: 3, 4 指令 C: 5, 6 section 执行指令 指令 A: 2, 3 指令 B: 4, 5 指令 C: 6, 7可见此时
需要增加一些硬件,控制电路更加复杂
-
二次重叠执行方式:分析指令时,即取出下一指令
gantt dateFormat x axisFormat %Q section 取指令 指令 A: 0, 1 指令 B: 1, 2 指令 C: 2, 3 section 分析指令 指令 A: 1, 2 指令 B: 2, 3 指令 C: 3, 4 section 执行指令 指令 A: 2, 3 指令 B: 3, 4 指令 B: 4, 5可见此时
CA6.2 流水方式
计算机中的流水线是将一个重复过程分解为若干子过程。每个子过程与其他子过程并行执行。
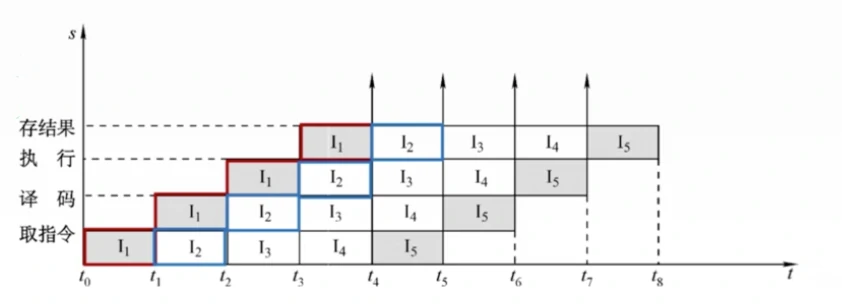
描述流水线的方法是 时空图。时空图又有两种描述方法。
-
时间 - 过程 方式:

(CA6_2 时空图1)
横坐标:表示时间。即各个任务在流水线经过的时间。图中红框、蓝框是两个任务。
纵坐标:表示空间。即流水线各个子过程。也称级、段、流水线深度。
-
时间 - 任务 方式:
(CA6_2 时空图2)
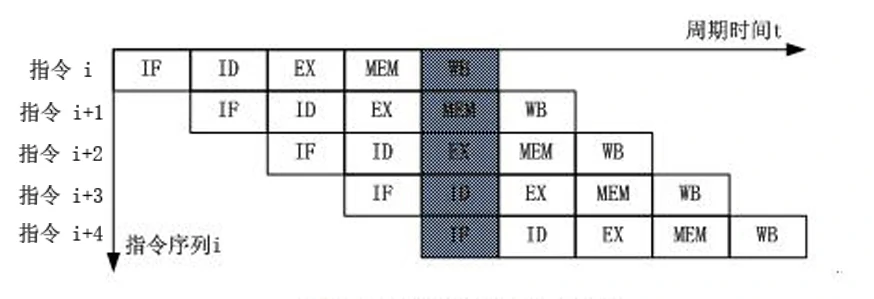
横坐标:表示时间。即各个任务或指令在流水线在该时刻对应的子过程。*(CA1.5 时空图1)中的红框任务大致对应(CA1.5 时空图2)*中的指令 i 一行。
在经典的 MIPS 五级流水线中:IF(取指)、ID(译码)、EX(执行)、MEM(存储器)、WB(写回)
纵坐标:可以表示 某个任务 或 某条指令。即流水线依次处理的任务或指令
流水线的特点:
- 基本组成采取 功能部件+锁存器 的模式。
- 各子功能部件都能独立工作,且各部件处理时间尽可能相等。
- 解决同步问题,保证以相同速度处理
- 解决访存冲突,允许不同指令同时读、写
流水线的不同分类方式:
-
按照流水线处理级别:部件级、处理机级、系统级。当一级流水线上的某过程不能在一个周期内完成时,可以将该过程其细分为下一级流水线。
-
按照流水线的功能多少:单功能(只能固定完成一种功能)、多功能(不同链接方式可完成不同功能)。
其中,多功能流水线又可按同一时间内各段间连接状态分为:静态多功能流水线(同一时间内,多功能结构只能按一种功能的连接方式工作)、动态多功能流水线(同一时间内,多功能结构可以按不同功能的连接方式工作)。
-
根据流水线的结构:线性流水线(无反馈回路)、非线性流水线(有反馈回路)
-
按照流水线控制方式:同步流水线(以共同的时钟控制周期)、异步流水线
-
按照流水线的数据类型:标量流水线、向量流水线
-
按照任务从输出端的流出顺序:顺序流水方式(先进先出)、乱序流水方式
描述流水线性能的一些指标:
-
吞吐率:单位时间流水线 完成的任务/输出结果 的数量
若 为任务数, 为流水线段数, 为时钟周期,则完成 个任务的时间
流水线吞吐率
最大吞吐率
各段时间不等时,实际吞吐率 ,最大吞吐率
-
加速比:完成一批任务的时间,与使用非流水线方式完成任务的时间,两者的比值
可见加速比
最大加速比
各段时间不等时,实际加速比 ,最大加速比
-
效率:流水线的设备利用率
可见效率
最高效率
各段时间不等时,实际效率 ,最大效率
流水线各段执行时间不同时,可以将瓶颈段 进一步细分,也能 设置重复瓶颈段。
流水线存在 相关(冲突,Hazard),使得指令流中的下一指令不能在指定的时钟周期内执行。为解决问题,约定了流水线 停顿:发生冲突后,流水线所有其他指令暂停。
这些相关有几种类型:
-
结构冲突:硬件资源不能满足指令重叠进行的需要而发生的停顿
解决方法 1:插入暂停周期(流水线气泡、气泡。所有后续流水线操作延后
解决方法 2:设置独立的 指令存储器 和 数据存储器,或设置独立的 指令 Cache 和 数据 Cache。
-
数据冲突:指令在流水线中重叠进行时,下一指令需要前面指令的结果而发生的停顿
两条指令的关系有:写后读、写后写、读后写、读后读。顺序情况下,写后读会产生数据冲突。
解决方法 1:由于寄存器的读写速度很快,可以约定:在时钟周期的上半周期写入数据,下半周期读出数据。这样只能解决同周期的读写先后问题。
解决方法 2:引入 旁路方式(定向技术、Bypass)。将某指令的计算结果从产生位置直接送到其他指令需要的位置,以避免停顿
-
控制冲突(全局性相关):已进入流水线的转移指令(分支指令或其他改变 PC 值的指令)与后续指令间的相关。
解决方法 1:加快和提前形成条件码。增加一些额外电路,使得各种分支的判断时间提前。
解决方法 2:猜测法。猜测后续分支,直接装入。在执行前可以验证。
解决方法 3:引入 延迟槽技术。更改指令的执行顺序,从其他地方调度代码(从前调度、从目标处调度、从失败处调度),在原本的停顿周期中执行这些调度代码。
解决方法 4:加快短循环程序的处理。
CA6.3 指令级高度并行的超级处理机
指令级并行(ILP,Instruction-Lecel Parallelism):使指令重叠以提高性能
有各种指令级并行技术:
- 超标量处理机:(硬件)具有多条流水线,因而能并发执行多个指令。
- 超长指令字:依靠编译器,把多条指令合并为一条指令。
- 超级流水线:将每个流水线段进一步细分。如此,在一个时钟周期内能分时流出多条指令。
CA6.4 向量流水处理机
向量处理机是有向量数据表示的处理机。
由于向量内部的元素很少相关,且一般执行同一操作,容易发挥流水线效能。故向量数据适宜使用流水线处理
向量的处理有几种方式,以计算 为例( 是 元向量):
-
横向(水平)处理方式:对于所有 ,计算
-
纵向(垂直)处理方式:先计算 ,再计算 。一般采用 垂直处理方式。
-
分组纵横处理方式
若向量的长度 太大,向量寄存器组无法容纳,则将向量分成多组。
每组内按 纵向处理方式,组间采用 横向处理方式。
向量处理中也可能发生冲突:
- V 冲突:并行工作的各向量指令的源向量或结果向量使用了相同的
- 功能冲突:同一功能部件被多个并行工作的向量指令使用
可以采取 链接 技术,对向量流水处理机进行优化:当两条指令出现 “写后读” 相关时,把其所用功能部件头尾相接,形成链接流水线,进行流水处理。
CA6.5 阵列处理机
阵列处理机是一种单指令流多数据流计算机。阵列处理机有两种构型:
- 分布式存储器
- 集中式共享存储器
阵列处理机的特点:
- 基于 有限差分、矩阵、信号处理、线性规划等问题 为背景。这些问题的共同特点是可以将其转化为对 数组 或 向量 的处理
- 单指令流多数据流
- 资源重复,而非时间重叠
- 利用并行性中的同时性
- 主要靠增大处理单元个数来提升运行速度,可扩展性更好
阵列处理机的 处理单元间、处理单元与处理分体间 都要通过 互连网络 进行通信。对互连网络的设计目标为:
- 不过分复杂,以降低成本
- 互连灵活,满足算法与应用需求
- 处理单元间信息交换步数尽可能少,以提高速度性能
- 可使用基本构件组合而成,使其模块性好
互连网络的操作方法有三种:同步、异步、同步异步组合。
互连网络的交换方式有三种:
- 线路交换:在源和目的地间建立直接通路。适用于大量数据传输。
- 包交换:将数据封装为数据包传送,不必建立实际的连接通路。适用于短数据信息传输
- 线路与包交换
为反映互联特性,每种互连网络 出端号 与 入端号(以二进制表示)的关系可用一组 互联函数 定义。
基本的 单级互连网络 有:
-
立方体:对于 个节点的立方体单级互连网络有 种互联函数。其中第 个() 是
-
PM2I:
-
混洗交换:包含 全混 和 交换 两个互连函数。
交换函数是
全混函数是
-
蝶形单机网络
在多级互连网络中的 交换开关 具有两个入端(上方 ,下方 )和两个出端(上方 ,下方 )。其四种状态(连接方式)为:
-
直连: 连接 ,同时 连接
-
交换: 连接 ,同时 连接
只具备 直连、交换 功能的交换开关称为 二功能交换单元
-
上播: 连接 ,同时 悬空
-
下播: 连接 ,同时 悬空
具备 直连、交换、上播、下播 功能的交换开关称为 四功能交换单元
在单级互连网络上进一步扩展就形成了 多级互连网络。包括:
-
多级立方体网络。包括使用 级控制 和 部分级控制 的 STARAN 网络、使用 单元控制 的 间接二进制网络 等
级控制:同一级所有开关使用一个控制信号控制,同级同一时刻只有一种状态
单元控制:所有开关都由独立信号控制,可以各自处于不同状态
部分级控制:第 级开关分别用 个信号控制。其中 , 是级数
多级立方体网络使用 二功能交换单元。第 级互联开关为交换状态时,实现 互连函数
-
多级混洗交换网络。又称 omega 网络。采用单元控制方式,每级含一个全混拓扑和随后的一列 个四功能交换单元。
-
多级 PM2I 网络、基准网络、多级交叉开关网络、多级蝶式网络等
在 共享主存构型的阵列处理机 中,存储器频宽匹配多个处理单元的速率,存储器就必须采用多体并行方式。必须保证各种访问模式下,存储器都能实现无冲突访问:
- 一维数组情况:并行存储区分体数为质数,就能尽量避免存储器访问冲突
- 二维数组情况:错位存放,且在多维数组行、列上采取不同错位方式。
- 二维数组大小不固定情况:将其转化为一维数组再存放
脉动阵列 也是一种阵列结构。数据按预先确定的 "流水 "方式在阵列的处理单元间有节奏地 “流动”。在数据流动的过程中,所有的处理单元同时并行地对流经它的数据进行处理,因而它可以达到很高的并行处理速度。脉动阵列有如下特点:
- 结构简单、规整,模块化强
- 数据流和控制流设计简单规整
- 具有极高的计算并行性
- 脉动阵列结构的构形与特定计算任务与算法密切相关